データ管理





















iPhoneマネージャー
iOSデータの管理iPhoneデータ復元
iOSデータを回復するiPhoneデータ消去ソフト
iOSデータを消去するAndroidマネージャー
Androidデータを管理するAndroidデータ復旧
Androidデータを回復するAndroidデータ消去ソフト
Androidデータを消去するスマホデータ転送
携帯電話間でデータを転送するデータ復旧
失われたデータを回復するiOSのバックアップと復元
iOSデータのバックアップと復元WhatsApp転送
WhatsApp チャットを転送するPCデータ復旧
PCデータを回復するAndroidのバックアップと復元
Androidデータのバックアップと復元iOS 用 WhatsApp 転送
iPhone WhatsAppチャットを転送するWhatsAppの回復
WhatsApp チャットを回復するWindowsバックアップ
PCデータのバックアップと復元データマネージャー
電話とデータの管理壊れたAndroidデータ復旧
壊れたAndroidを回復するMacのバックアップ
Mac データのバックアップと復元パーティションマネージャー
PC上のパーティションを管理する写真の回復
写真とビデオを回復するデータ消去
データ、フォルダー、ドライブの消去
ユーティリティ










マルチメディア














画面録画ソフト
PCで画面を録画ビデオコンプレッサー
ビデオサイズを圧縮するビデオ透かしメーカー
動画に最適なウォーターマーク追加ツールビデオエディター
簡単なビデオ編集ビデオマージ
2 つ以上のビデオを結合するGIFメーカー
ビデオ/写真から GIF を作成ビデオダウンローダー
どこでもビデオをダウンロードビデオトリマー
ビデオクリップのトリミングと編集背景ノイズの除去
オーディオ/ビデオから背景ノイズを除去するビデオコンバーター
AIビデオコンバータービデオクロッパー
ビデオをトリミングするのに最適なビデオ クロッパーボリュームブースター
音量を上げたり下げたりするのに最適なサウンドブースタービデオプレーヤー
あらゆる映画を視聴するのに最適なメディア プレーヤービデオスピードコントローラー
ビデオの速度を上げるまたは遅くする
AI














リソース
サポート
背景除去
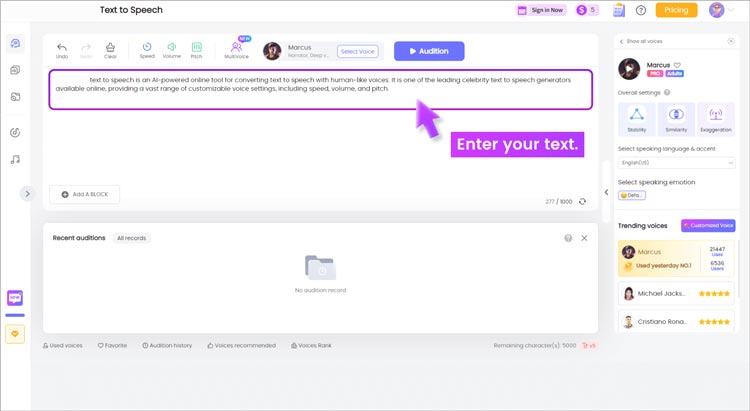
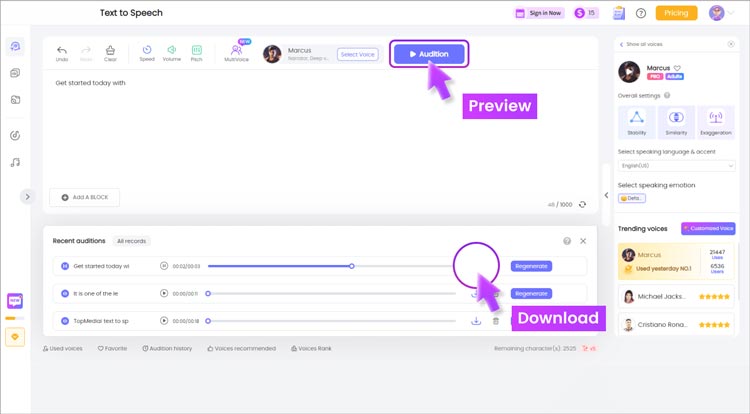
画像の背景を削除するテキスト読み上げ
AI テキスト読み上げジェネレーターファイルの修復
ファイル/ビデオ/写真の復元ウォーターマークリムーバー
写真とビデオの透かしを削除する音声ジェネレーター
AI音声ジェネレーター&クローナーAIフォトエディター
AI 画像エディターで写真を編集するオブジェクトリムーバー
ビデオオブジェクト/人物の削除ボイスチェンジャー
リアルタイムAIボイスチェンジャーサムネイルメーカー
ベスト YouTube サムネイル メーカーフォトエンハンサー
ベスト AI 画像エンハンサーAI音楽ジェネレーター
最優秀AIソングジェネレーターAIライター
ベスト AI ライティング ジェネレータービデオ強化ツール
ビデオの強化と調整AIビデオジェネレーター
AI でテキストを動画に変換



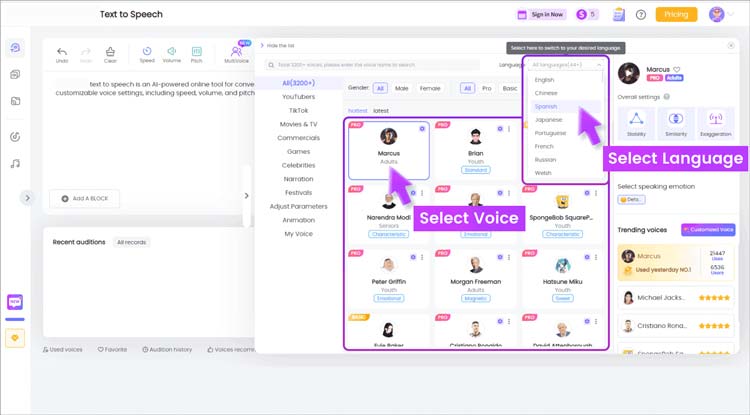
 ボイスセレクション
ボイスセレクション 多言語サポート
多言語サポート AI音声クローン作成
AI音声クローン作成 カスタムボイス設定
カスタムボイス設定 APIの統合
APIの統合 クロスプラットフォームアクセス
クロスプラットフォームアクセス インタラクティブな学習
インタラクティブな学習 アクセシビリティ機能
アクセシビリティ機能 多彩な用途
多彩な用途